Text Web Mining & Data Mining Notes and Records
Text Web Mining
Training Skills
How to use colab to run ML tasks
- click “Runtime” -> “Change Runtime Type” -> select GPU or TPU
- use code below to check GPU status
!nvidia-smi - build connection between google drive files and this notebook
from google.colab import drive
drive.mount(‘/content/drive/‘) - change dir
import os
os.chdir(“/content/drive/My Drive/Colab Notebooks/…/“) - Do not use same browser to run both Jupyter and Colab, might crash
Take Home Project 2 - sentiment classifier
preperation
- good examples and guide: bentrevett / pytorch-sentiment-analysis / Sentiment Analysis with Pytorch — Part 3— CNN Model / xalanq
/ chinese-sentiment-classification / slaysd
/ pytorch-sentiment-analysis-classification - NN, RNN, BERT - given Jupyter files
- modify CNN Jupyter files
- change surname model to sentiment model - character level tokens
- online reference: 3 kind of outcome sentiment classifer
- use weka:
weka to do deep learning / official guide of installing / how to quick install weka deep learning toolkit
Further work direction
- coBerta kaggle example using coBerta
- weka preprocessing + bert weka preprocessing
- evaluation ambert evaluation / ambert discussion in zhihu
Group Project : Taylor Swift lyrics generator
method: RNN LSTM GPT2
- LSTM github good instance
- LSTM github detailed instance - Tom-Chang-Deep-Lyrics | 基於 LSTM 深度學習方法研發而成的張雨生歌詞產生模型,致敬張雨生。
- GPT2 styled lyrics generator - github + colab
Lab-no2 adjust hyperparameters to get higher accuracy and lower loss
Optimize target: Classifying Surnames with a Multilayer Perceptron
original code from the textbook website, https://github.com/joosthub/PyTorchNLPBook.
Build the best model (based on test loss and test accuracy) by exploring following options:
- learning_rate
- batch_size
- dropout (use only if it helps)
- batch norm (use only if it helps)
- weight_decay (L2 regularization) (use only if it helps)
- hidden_dim
- Note that it is not necessary to adjust other parameter values even though you are allowed to do so.
Values of given parameters
Thanks for Professor Jin’s suggestion and instruction, I would choose to share some findings when using a slightly different input dataset later on, but not share my answer directly.
Best outcomes
Test loss: 1.61;
Test Accuracy: 57.789
Taking “drewer” as an example
Top 15 predictions:
drewer -> German (p=0.46)
drewer -> English (p=0.35)
drewer -> Dutch (p=0.06)
drewer -> Scottish (p=0.04)
drewer -> Czech (p=0.04)
drewer -> Polish (p=0.01)
drewer -> Spanish (p=0.01)
drewer -> French (p=0.01)
drewer -> Portuguese (p=0.01)
drewer -> Russian (p=0.00)
drewer -> Irish (p=0.00)
drewer -> Chinese (p=0.00)
drewer -> Japanese (p=0.00)
drewer -> Italian (p=0.00)
drewer -> Arabic (p=0.00)
Tips
- Using VPN would block anaconda-navigator startup, because VPN would probably take up the specific localhost port.
- homebrew to solve environment path problem. Install graphviz
1
2brew install graphviz
pip install graphviz
Data Mining
Useful Info
- Learn - University of Waikato. Course Link: Youtube /
Youtube / Learn Course Link: Youtube - Dataset repository of UCI
Classification Problem
dataset
Final result online presentation (Jupyter)
Basic acknowledge and demo testing
Environment: anaconda-nevigator / Jupyter-pytorch / sklearn
Build project
Environment: Docker / Jupyter-tensorflow / sklearn / original reference
- preprocessing
- train and test
- gather data and outcomes
- compare and analysis
- draw ROC plot
Additional way: use Weka to generate result
- convert .data file into .arff file
.data -> .csv (use “sublime text”) -> add label names in .csv (use “sublime text” but not “numbers”) -> use tools to change to .arff, remember to select first row contains labels. - use Weka to genarate
- compare and analysis
Reference
- Use conda environment when facing conda install inconsistency
- Using label encoding function would lead to error below. can be fixed by remove the null values in dataset. Basic guide Application guide
1
Encoders require their input to be uniformly strings or numbers. Got ['float', 'str']
- Use MicroSoft and Weka to convert xls/csv to arff / CSV2ARFF website / ARFF2CSV
- Label encoding & One-Hot encoding
- Pandas missing value process methods
Association Problem
Weka
- Use Java to launch Weka.jar / Youtube example video / Weka-Apriori parameter meaning / Weka Javadoc - Association
- output runtime in association progress
Preparation
- Learn - University of Waikato. Course Link: Youtube /
Youtube / Learn Course Link: Youtube - Dataset repository of UCI
- Small example of running Apriori in Websit javaTpoint
- Detailed ppt of Association Rule Mining from USTC
- Complexity
Apriori
Algorithm steps
Step-1: Determine the support of itemsets in the transactional database, and select the minimum support and confidence.Step-2: Take all supports in the transaction with higher support value than the minimum or selected support value.
Step-3: Find all the rules of these subsets that have higher confidence value than the threshold or minimum confidence.
Step-4: Sort the rules as the decreasing order of lift.
Apriori in WEKA
- WEKA use data set in .arff format
tips: 1) use csv2arff or arff2csv- can also use arff functions to change xls and csv files directly into arff files
- There are 12 parameters could be set before running Apriori reference
- Apriori properties in WEKA.)
Original dataset test information
| Time | labor | breast-cancer | wisconsin-breast-cancer | hypothyroid | mushroom | letter | adult |
|---|---|---|---|---|---|---|---|
| attribute number | 17 | 10 | 10 | 30 | 23 | 16 | 15 |
| instance number | 57 | 286 | 699 | 3772 | 8124 | 20000 | 32561 |
| setting 1 | 263 | 302 | 296 | 372 | 343 | 526 | 746 |
| setting 2 | 289 | 337 | 314 | 587 | 723 | 2493 | 4633 |
| brute estimate | 16246 | 81513 | 199221 | 1075057 | 2315421 | 5700200 | 9280211 |
Setting 1: lowerBoundMinSupport = 0.5; classindex = -1; delta = 0.05; minConfidence = 0.9; minRules = 100
Setting 2: lowerBoundMinSupport = 0.1; classindex = -1; delta = 0.01; minConfidence = 0.95; minRules = 200
The reason for disturbance in the plot is that Apriori in WEKA starts with the upper bound support and incrementally decreases support. The algorithm stops when either the specified number of rules are generated, or the lower bound for min is reached. So the abnormal run time is due to the different stop criteria[1].
Additional dataset test information
In addition, I choose a set of datasets with similar structure, the experimental outcome fits the theoretical prediction very well.
| Dataset | spectrum disorder screening - adolescent | spectrum disorder screening - children | spectrum disorder screening - adult | absent at work | SouthGermanCredit | mushroom |
|---|---|---|---|---|---|---|
| attribute | 21 | 21 | 21 | 21 | 21 | 22->21 |
| instance | 104 | 292 | 704 | 740 | 1000 | 8124 |
| time / setting 1 | 303 | 320 | 319 | 317 | 387 | 409 |
| time / setting 2 | 307 | 346 | 372 | 472 | 953 | 976 |
Brute force estimation
- The brute force step can be summed up as follows. Firstly, generate all association rules. Then, determine whether the item sets fit the criteria by checking through all the instances.
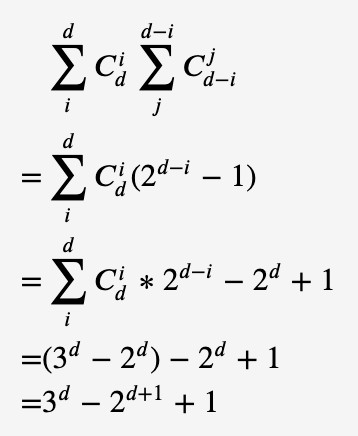
- Set d as the number of attributes and N as the number of instances, then the number of all association rules is [3 ^ d - 2 ^ (d + 1) + 1]. The overall time complexity is [k * {3 ^ D-2 ^ (D + 1) + 1} * N]. In test experiment, it takes 1ms to estimate the brute force time of D = 4, n = 4, so K is 0.005. When d = 10, n = 57, the total time of “labor” dataset spent could be estimated as 16.246s, so as to other datasets.
Plot
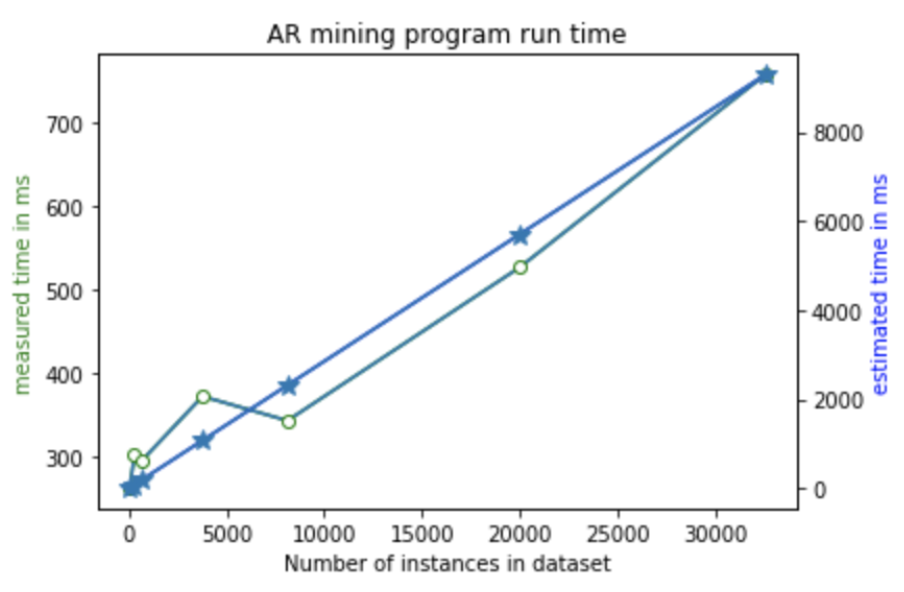
Error analysis
Reference
- http://facweb.cs.depaul.edu/mobasher/classes/ect584/WEKA/associate.html#:~:text=The%20upper%20bound%20for%20minimum,to%200.05%20or%205%25).
- https://www.cnblogs.com/en-heng/p/5719101.html